EPUB Indexes 1.0
Draft Specification 14 January 2014
- This version
- http://www.idpf.org/epub/idx/epub-indexes-20140114.html
- Latest version
- http://www.idpf.org/epub/idx/epub-indexes.html
- Previous version
- http://www.idpf.org/epub/idx/epub-indexes-20131104.html
A diff of changes from the previous version is also available.
Please refer to the errata for this document, which may include some normative corrections.
Copyright © 2010-2013 International Digital Publishing Forum™
All rights reserved. This work is protected under Title 17 of the United States Code. Reproduction and dissemination of this work with changes is prohibited except with the written permission of the International Digital Publishing Forum (IDPF).
EPUB is a registered trademark of the International Digital Publishing Forum.
Table of Contents
- 1. Overview
- 2. Indexes Definition
-
- 2.1. Introduction
- 2.2. Content Documents and Components
- 2.3. Identification of an Index
- 2.4. The Navigation Document
- 3. Conformance Criteria
- A. Schema for Indexes in EPUB Content Documents
- B. Examples
- C. Reading System Implementation Suggestions
-
- C.1. General Reading System Features Relative to Indexes
- C.2. Search Parameters
- C.3. Index Term Search
- C.4. Index Locator Search
- C.5. Highlighting of Locator Ranges
- C.6. Filtering of Indexes
- C.7. Provision of Additional Information about Locator Targets
- C.8. Enhancements to Term Categories and Generic Cross-Reference Targets
- C.9. Improved Index Navigation
- D. Alphabetical list of epub:types defined in this specification
- E. Index to this specification
- F. Acknowledgements and Contributors
- References
› 1 Overview
This specification refers to EPUB Publications 3.0.1 [Publications301]. Elements referred to herein are [HTML5] elements.
› 1.1 Purpose and Scope
This section is informative
The purpose of this specification is to define a consistent way of encoding the structure and content of indexes in EPUB Publications, in a manner that enables indexes to be rendered on all EPUB Reading Systems and handled in an optimal manner on EPUB Reading Systems that conform to the specification. Reading Systems can exploit this encoding to offer not only the benefits of a print index but also interactive functionality and features not possible in a print book.
There are four ways of finding information in published content: using a table of contents, browsing (including sequential reading), searching, and using an index. These four methods have different characteristics and serve different purposes. The table of contents provides a structural overview of the content covered in the publication, listed in the same order and using the same words as in the content itself. Browsing allows the user to skim the whole publication, and to dip into portions of interest. Searching allows the user to find locations where the search string matches (or nearly matches) the words found in the publication, but often offers no test of significance or uniqueness, results in too many matches, or misses coverage that employs either near-synonyms or hierarchically different terminology' (e.g., searching for 'war' may not find 'conflict' or 'hostilities'; searching for 'dogs' may not find 'spaniels', 'retrievers' or 'dachshunds').
Indexes have several important characteristics that together distinguish them from the other three methods. First, indexes provide direct topic-based access throughout the content of a publication. Second, indexes include topics at different degrees of precision, both general (broad) and specific. Third, indexes show relationships between topics. Fourth, indexes contain entries only for content that is considered to be substantive, selected and organized by a human indexer.
Indexes are explorable documents. An index helps the user find needed information not only by providing carefully selected terms, but also through a network of cross-references that lead the user to preferred or related terms, and by the use of subentries that offer more fine-grained breakdowns of discussion of a topic. Because of this, indexes also provide a sense of the depth of topic coverage in a book, and can therefore be a useful marketing tool.
Indexes are focused on meanings, not simply character strings (like a search), and include as access points not only words explicitly used in the publication but also alternative terms that users might think of, so that the user is less often left with "Sorry, no such term." An index often employs special features to show the user in advance what sort of content they can expect if they follow a link (e.g., an italicized locator may indicate that the locator target is a figure).
Indexes are highly useful specialized navigational tools that make published content more accessible. The EPUB standard makes indexes even more useful by providing access to them from all parts of a publication, by integrating them with additional navigation approaches such as search, and by making possible innovative means of access that are not available with print books (e.g., filtering of an index to show only figure references, or display of all index entries applicable to a selected range of text).
This document does not address the interaction between an index and a reading system's search, but some suggestions regarding how they could interact may be found in Appendix C. Reading System Implementation Suggestions, sections C.3 and C.4.
This document does not address index content or presentation. Guidelines for the content, creation and organization of indexes may be found in ISO 999: Information and documentation -- Guidelines for the content, organization and presentation of indexes [ISO999] and in NISO Technical Report 2: Guidelines for Indexes and Related Information Retrieval Devices [NISOTR02].
› 1.2 Terminology
If a term listed in this section is discussed or defined in more detail in a later section, the section number is given in parentheses.
note
The following definitions are intended for clarity within the context of this specification only, and may vary from their usage in other contexts.
- child entry
-
An entry that is an immediate descendent of another entry; these are often referred to in the publishing industry as subentries.
- content document
-
An XHTML Content Document [ContentDocs301] as used in EPUB Publications [Publications301].
- cross-reference (2.2.7)
-
A cross-reference directs the user to one or more cross-reference targets in the same index or another index. It directs the user from one term to (1) one or more related terms or term categories (which provide additional information), or (2) one or more preferred terms or term categories (when the user looks up one term but the concept is indexed under a different term). Cross-references usually begin with lead-in words, for example "see" or "see also."
In the following examples, the main entry is in plain text and the cross-reference is in bold text.
Peking. See Beijing . [directs user to a preferred term]
battles. See names of specific battles . [directs user to a preferred term category]
sweet potatoes, 63. See also yams . [directs user to a related term]
potatoes, 55-59, 61. See also specific potato cultivars . [directs user to a related term category]
yams, 82. See also names of yam cultivars; Yam Festival (Ghana); yam powder [directs user to both a related term category and two related terms]
- cross-reference target (2.2.7)
-
A term or term category that is pointed to by a cross-reference.
- editor's note (2.2.3)
-
Explanatory text accompanying a term. Sometimes called "editorial note" or "scope note."
- entry (2.2.3)
-
A term plus any associated locator(s), cross-reference(s), editor's note(s), and child entries. A term cannot stand alone as an entry; it
musthave at least one locator, cross-reference, editor's note, or child entry. - generic cross-reference target (2.2.8)
-
A cross-reference target that is a term category , rather than a term.
- group title (2.2.2)
-
The title of an index group.
- head notes (2.2.1)
-
Optional informative content appearing at the top of an index to enable the user to make optimal use of the index, such as the index title, explanation of usage, format of locators, coverage of information, legend, etc.
- index
-
The entire index, consisting of an optional head notes section and one or more entries.
- index group (2.2.2)
-
A series of consecutive main entries within the index, e.g. all main entries beginning with the letter "A", with an optional group title.
- index title (2.2.1)
-
The title of an index, for example "Index of First Lines" or "Name Index."
- legend (2.2.1)
-
A list of abbreviations or special indicators used in the index (such as prefixes to locators, special symbols, special text formatting, initials/abbreviations, etc.) and their meanings.
- locator (2.2.4)
-
Connection between a term and the location of the indexed content.
- locator range (2.2.5)
- locator target
-
The piece of content that is pointed to by a locator. It can be either a single point or a range of content.
- main entry
-
An entry that has no parent entry.
- parent context
-
A property [Publications301] carried by the nearest ancestor element being semantically inflected [ContentDocs301] , either implicitly or explicitly via an epub:type attribute defined in this specification.
- term
-
Word, phrase, string, glyph or image representing the indexable topic -- e.g., a name, a place, a concept, etc.
- term category (2.2.8)
-
Category applied to terms to create an association between them; e.g., the term category "flowers" might be used to associate the index terms "daisies", "lilies", and "roses". These term categories
maybe drawn from a controlled vocabulary, ormaybe developed as needed for a given index.
› 1.3 Conformance Statements
The keywords MUST, MUST NOT, REQUIRED, SHALL, SHALL NOT, SHOULD, SHOULD NOT, RECOMMENDED, MAY, and OPTIONAL in this document are to be interpreted as described in [RFC2119].
All sections of this specification are normative except for examples, or except for sections identified by the informative status label "This section is informative". The application of informative status to sections and appendices applies to all child content and subsections they may contain.
This specification maintains backwards-compatibility with the index semantics already included in the EPUB Structural Semantics Vocabulary [StructureVocab], while refining and expanding on them.
› 1.4 Typographic Conventions
The following typographic conventions are used in this specification:
-
markup -
All markup (elements, attributes, properties), code (JavaScript, pseudo-code), machine processable values (string, characters, media types) and file names are in red-orange monospace font.
-
markup -
Links to markup and code definitions are underlined and in red-orange monospace font. Only the first instance in each section is linked.
-
http://www.idpf.org/ -
URIs are in navy blue monospace font.
- hyperlink
-
Hyperlinks are underlined and in blue.
- [reference]
-
Normative and informative references are enclosed in square brackets.
- Term
-
Terms defined in the Terminology are in capital case.
- Term
-
Links to term definitions have a dotted blue underline. Only the first instance in each section is linked.
-
Normative element, attribute and property definitions are in blue boxes.
Informative markup examples are in white boxes.
note
Informative notes are in yellow boxes with a "Note" header.
caution
Informative cautionary note are in red boxes with a "Caution" header.
› 2 Indexes Definition
› 2.1 Introduction
This section is informative
At its simplest, an index consists of one or more entries, possibly accompanied by additional information (head notes) that will help the human reader use the index effectively. Example 1 shows an entry with all possible component parts. Entries consist of a term, such as "cats", followed by one or more of the following: (1) locator(s) showing where in the publication's content discussion of that topic occurs (e.g., "77-80"); (2) subentries that refine or narrow the topic (e.g., "diet"); (3) a reference directing the user to another entry (e.g., "see also wildcats"); (4) editorial notes (e.g., "domestic cats from the subfamily Felinae"). Note that subentries (i.e., descendant or child entries) provide a hierarchy of topical structure, and are themselves followed by one or more of the four items listed above.
Example 1, entry with all possible components:
cats Ed. Note: domestic cats from the subfamily Felinae coat types, 7:5-7:6 diet, 7:1 lifespan, 7:7-7:9 training, 8:1 see also wildcats
Index entries are displayed by the reading system in the order they appear in the index file(s).
A user can browse an index sequentially to locate desired information, similar to reading a chapter of a book ("chapter-like index") or paging through a dictionary, but this specification also proposes encoding that would enable more interaction between user, index and text (see sections 2.2.6 Locator Target Structural Semantics, 2.2.8 Term Categories and Generic Cross-Reference Targets, and Appendix C. Reading System Implementation Suggestions for more on this).
› 2.2 Content Documents and Components
› 2.2.1 Index, Index Head Notes
An EPUB Publication may contain zero or more indexes. An index may consist of one or more content documents, or it may be embedded within a content document that also contains other indexes or other types of content (e.g., a chapter). Wherever it occurs, an index must be wrapped in an element whose epub:type attribute has the value index. If the index is made up of one or more entire content documents, the body element must be used ( <body epub:type="index"> ). If an index, or a part of an index, is embedded within a content document that also contains other types of content, any [HTML5]
sectioning content element may be used to wrap it (for example, <section epub:type="index"> ).
- Structural Semantics Vocabulary
-
index - Definition
-
Outermost
epub:typevalue for an index - HTML Usage Context
-
Required on element wrapping an index
Use on any [HTML5] sectioning content element or
bodyMay contain one and only one [HTML5] heading content element
May contain one and only one element carrying the child semantic
index-headnotesMust contain one and only one element carrying the child semantic
index-entry-listOR one or more elements carrying the child semanticindex-groupsMust not contain any other element carrying a child semantic property defined in this specification
An element whose epub:type attribute value includes index
may contain one element whose epub:type attribute value includes index-headnotes. Head notes are often used in indexes to convey additional information necessary for the user to make the most effective use of the index. The head notes section is optional. If used, it consists of an [HTML5]
header
element or [HTML5]
sectioning content element whose epub:type attribute value includes index-headnotes. This element may contain a legend or any other pertinent or useful information.
- Structural Semantics Vocabulary
-
index-headnotes - Definition
-
Narrative or other content to assist users in interpreting or using the information in the index
- Required Parent Context
-
index - HTML Usage Context
-
Use on [HTML5]
headeror sectioning content elementMay contain one or more elements carrying the child semantic
index-legendsMay contain any valid [HTML5] elements
Example 2, typical head notes section containing narrative text and index title:
<header epub:type="index-headnotes"> <h1>Subject Index</h1> <p>This is an index to the main text of the book; content in the appendices has not been indexed. References are to section and paragraphs. The number preceding the colon is the number of the section; the number following the colon is the paragraph number within the section.</p> <p>Alphabetization is word-by-word: New York comes before Newtown.</p> </header>
The head notes may contain a legend (a listing of abbreviations, symbols or special formatting used in the index, and their meanings) indicated by use of the epub:type attribute value index-legend. Since legend data consists of one or more name/value pairs, the data itself should be encoded using the [HTML5] definition list (dl, dt, dd) structure. This makes the legend machine-readable, enabling reading systems to manipulate it.
- Structural Semantics Vocabulary
-
index-legend - Definition
-
List of symbols, abbreviations or special formatting used in the index, and their meanings
- Required Parent Context
-
index-headnotes - HTML Usage Context
-
Use on any [HTML5] sectioning content element or on
dl
Example 3, legend on dl element:
<header epub:type="index-headnotes"> <p>The following abbreviations are used in this index.</p> <dl epub:type="index-legend"> <dt>Civ. R.</dt><dd>Civil Rule</dd> <dt>Crim. R.</dt><dd>Criminal Rule</dd> <dt>§</dt><dd>Statute</dd> </dl> <p>The following formatting conventions are used in this index-</p> <dl epub:type="index-legend"> <dt>bold text</dt><dd>main discussion/definition of topic</dd> <dt>italic text</dt><dd>indicates figure</dd> <dt>'t' following a locator</dt><dd>indicates table</dd> </dl> </header>
Example 4, legend on section element:
<header epub:type="index-headnotes> <p>The following abbreviations are used in this index.</p> <section epub:type="index-legend"> <h2>Abbreviations and definitions</h2> <dl> <dt>Civ. R.</dt><dd>Civil Rule</dd> <dt>Crim. R.</dt><dd>Criminal Rule</dd> <dt>§</dt><dd>Statute</dd> </dl> </section> </header>
Following the optional head-notes is the bulk of the index, comprised of one or more entries, as described in the following sections 2.2.2 and 2.2.3.
Example 5, with index head notes, index comprises entire content document:
<body epub:type="index"> <header epub:type="index-headnotes"> ... </header> ...<!-- entries go here --> </body>
Example 6, without index head notes, index comprises entire content document:
<body epub:type="index"> ...<!-- entries go here --> </body>
Example 7, with index head notes, index comprises part of content document:
<section epub:type="index"> <header epub:type="index-headnotes"> ... </header> ...<!-- entries go here --> </section>
Example 8, without index head notes, index comprises part of content document:
<section epub:type="index"> ...<!-- entries go here --> </section>
› 2.2.2 Index Groups
Index groups
may be used to wrap groups of consecutive main entries, for example all entries beginning with "A". An index group is created by use of the epub:type attribute value index-group.
If index groups are used, then every main entry must be part of a group. In other words, for any element whose epub:type attribute value includes index, either (1) all children that contain entries must have an epub:type attribute value of index-group or (2) there must be only one child that contains entries and it must be a ul element whose epub:type attribute value will have the implied value of index-entry-list (see 2.2.3 Entries and Terms for entry list information).
An index group may contain, as its first child, a title for that group.
- Structural Semantics Vocabulary
-
index-group - Definition
-
Series of consecutive main entries that share a common characteristic
- Required Parent Context
-
index - HTML Usage Context
-
Use on any [HTML5] sectioning content element
May contain an [HTML5] heading content element
Must contain one and only one element carrying the child semantic
index-entry-listMust not contain any other element carrying a child semantic property defined in this specification
Example 9, index groups:
... <section epub:type="index"> ... <section epub:type="index-group"> <h1>A</h1> ...[entries beginning with "A"] </section> <section epub:type="index-group"> <h1>B</h1> ...[entries beginning with "B"] </section> </section> ...
› 2.2.3 Entries and Terms
Regardless of whether main entries are grouped or ungrouped as described above, a list of index entries
must be encoded using the ul element; each index entry
must be encoded using the li element.
An epub:type attribute value of index-entry-list is implied for all ul elements within an index, unless (1) the ul occurs inside index-headnotes or (2) a different value is explicitly given or otherwise implied by this specification.
- Structural Semantics Vocabulary
-
index-entry-list - Definition
-
Series of consecutive main entries, or of consecutive subentries
- Required Parent Context
-
index,index-group, orindex-entry - HTML Usage Context
-
Use on
ulelement.Implied when ancestor is of type
indexexcept withinindex-headnotesMust contain one or more elements carrying the child semantic
index-entryMust not contain any other element carrying a child semantic property defined in this specification
An epub:type attribute value of index-entry is implied for all li elements whose parent ul implicitly or explicitly includes an epub:type attribute value of index-entry-list.
- Structural Semantics Vocabulary
-
index-entry - Definition
-
One entry
- Required Parent Context
-
index-entry-list - HTML Usage Context
-
Use on
lielementImplied when parent
ulis of typeindex-entry-listMust contain one element carrying the child semantic
index-termMust contain at least one of the following:
only one element carrying the child semantic index-entry-listonly one element carrying the child semantic index-locator-listOR a mix of one or more elements carrying the child semanticsindex-locators andindex-locator-rangesonly one element carrying the child semantic index-editor-noteone or more elements carrying the child semantic index-xref-preferredOR one or more element carrying the child semanticindex-xref-relatedMust not contain any other element carrying a child semantic property defined in this specification
- Structural Semantics Vocabulary
-
index-term - Definition
-
Word, phrase, string, glyph or image representing the indexable content
- Required Parent Context
-
index-entry,index-xref-preferred, orindex-xref-relatedAlternatively, may be carried on same element as
index-entry,index-xref-preferred, orindex-xref-related - HTML Usage Context
-
Use on any [HTML5] phrasing content element, typically
span
An entry must contain one and only one element with an epub:type attribute value of index-term, plus one or more of the following: (1) one or more subentries (in an element whose epub:type attribute includes index-entry-list); (2) one or more locators (see 2.2.4 Locators); (3) one editor's note (an element whose epub:type attribute value includes index-editor-note); (4) one or more cross-references (see 2.2.7 Cross-references).
Example 10 shows the first case, an entry that contains subentries. As noted above, the epub:type values index-entry-list and index-entry are implied in certain cases and need not be explicitly stated; Example 10 does state them explicitly for purposes of illustration, but later examples do not.
Example 10, term plus subentries:
Entry as it might be displayed to user:
Black, John, birth, 75 death, 78
Entry as coded with all epub:type values explicitly stated:
<ul epub:type="index-entry-list"> <li epub:type="index-entry"> <span epub:type="index-term">Black, John</span> <ul epub:type="index-entry-list"> <li epub:type="index-entry"> <span epub:type="index-term">birth</span> <a epub:type="index-locator">¶75</a> </li> <li epub:type="index-entry"> <span epub:type="index-term">death</span> <a epub:type="index-locator">¶78</a> </li> </ul> </li> </ul>
Examples 11 through 13 show the other three epub:type values that can be used within an entry. As stated above, a given entry may contain elements with several of these values in any combination. In the following examples, epub:type attribute values index-entry-list and index-entry are implied, and not shown.
Example 11, term plus locator (see 2.2.4 Locators for locator specifics):
<ul> <li> <span epub:type="index-term">Heston, Charlton</span> <a epub:type="index-locator" href="...">¶53</a> </li> </ul>
- Structural Semantics Vocabulary
-
index-editor-note - Definition
-
Editorial note pertaining to a single entry
- Required Parent Context
-
index-entry - HTML Usage Context
-
Use on any [HTML5] flow content element
Example 12, term plus editor's note:
<ul> <li> <span epub:type="index-term">Heston, Charlton</span> <span epub:type="index-editor-note">Charlton Heston (1923-2008), actor in numerous American films.</span> </li> </ul>
Example 13, term plus cross-reference (see 2.2.7 Cross-references for specifics):
<ul> <li> <span epub:type="index-term">Peking</span> <span epub:type="index-xref-preferred">See <a epub:type="index-term" href="...">Beijing</a>. </span> </li> </ul>
A variant of a regular index is the "glindex," a combined glossary and index that is sometimes used as a way of combining end matter and/or saving space. In a glindex, some or all of the main entry terms are followed by a definition, as might be seen in a glossary. In this case the glossary properties from the EPUB Structural Semantics Vocabulary [StructureVocab] should be used in conjunction with the index properties outlined in this specification, as shown in Example 14.
Example 14, combined glossary and index ("glindex"):
<body epub:type="glossary index">
...
<ul epub:type="index-entry-list">
<li><!-- implied epub:type of index-entry -->
<span epub:type="index-term glossterm">adjective</span>
<span epub:type="index-locator-range">75-77</span>
<span epub:type="glossdef">A word that modifies, quantifies, identifies, or describes a noun or words acting as a noun.</span>
</li>
</ul>
</body>
› 2.2.4 Locators
A locator is represented by an [HTML5]
a
element with an implied or explicit epub:type value of index-locator. A locator typically has an [HTML5]
href attribute pointing to some location within the EPUB Publication; when it has no href attribute value, the locator will not be actionable. Reading Systems must interpret anchors without an explicit or implied epub:type as generic [HTML5] hyperlinks.
note
Paper books commonly use page, section or paragraph numbers as locators. An ebook may choose to use legacy page numbers, paragraph numbers, section numbers, simple sequential numbers, terms, icons, or anything else desired as the rendered part of the locator.
- Structural Semantics Vocabulary
-
index-locator - Definition
-
Reference to indexed content
- Required Parent Context
-
index-entry,index-locator-list, orindex-locator-range - HTML Usage Context
-
Use on [HTML5]
aelementImplied when parent context is
index-locator-listorindex-locator-rangeMay have the
hrefattribute
Example 15, locators without href:
As coded:
<a epub:type="index-locator"><img alt="phone" src="phone-icon.png"/></a> ... <a epub:type="index-locator">35</a> ... <a epub:type="index-locator">II:14</a>
As displayed (one possible method):
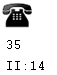
Example 16, locators with href:
As coded:
<a epub:type="index-locator" href="..."><img alt="phone" src="phone-icon.png"/></a> ... <a epub:type="index-locator" href="...">35</a> ... <a epub:type="index-locator" href="...">II:14</a>
As displayed (one possible method):

The index term may also serve as the human-readable string for the locator:
Example 17, term also serving as locator text:
As coded:
<span epub:type="index-term"> <a epub:type="index-locator" href="...">Berlin</a> </span> <span epub:type="index-term"> <a epub:type="index-locator" href="...">Paris</a> </span>
As displayed (one possible method):
Berlin
Paris
The epub:type attribute value index-locator
may be explicitly set on each a element, as shown in the above examples. Alternatively, an epub:type of index-locator is implied when an a element has a parent context of index-locator-list or index-locator-range. Locator lists are discussed below; see section 2.2.5 Locator Ranges for encoding locators that are a range.
- Structural Semantics Vocabulary
-
index-locator-list - Definition
-
Series of sequential
index-locators orindex-locator-ranges - Required Parent Context
-
index-entry - HTML Usage Context
-
Use on [HTML5]
ulelementMust contain one or more elements carrying the child semantic
index-locator
Example 18, value of index-locator explicitly set:
<ul epub:type="index-entry-list"> <li epub:type="index-entry"> <span epub:type="index-term">Heston, Charlton</span> <a epub:type="index-locator" href="...">53</a> <a epub:type="index-locator" href="...">76-79</a> </li> <li> <span epub:type="index-term">Howard, Leslie</span> <a epub:type="index-locator" href="...">62</a> </li> </ul>
Example 19, value of index-locator implied through use of index-locator-list:
<ul epub:type="index-entry-list"> <li epub:type="index-entry"> <span epub:type="index-term">Heston, Charlton</span> <!-- locators wrapped in locator-list --> <ul epub:type="index-locator-list"> <!-- epub:type value index-locator is implied for all a elements due to ancestor with epub:type value locator-list --> <li><a href="...">53</a></li> <li><a href="...">76-79</a></li> </ul> </li> <li epub:type="index-entry"> <span epub:type="index-term">Howard, Leslie</span> <ul epub:type="index-locator-list"> <li><a href="...">62</a></li> </ul> </li> </ul>
Nesting of lists of locators is permitted if desired for some reason such as applying different classes to different subsets of locators, as shown in Example 20.
Example 20, locators in nested lists:
<ul epub:type="index-locator-list"> <li> <ul class="..."> <!-- epub:type value index-locator is implied for all a elements due to ancestor with epub:type value locator-list --> <li><a href="...">3:5</a></li> <li><a href="...">9</a></li> <li><a href="...">14</a></li> </ul> </li> <li> <ul class="..."> <li><a href="...">5:7</a></li> <li><a href="...">9</a></li> </ul> </li> </ul>
› 2.2.5 Locator Ranges
In the above examples, some of the locators refer to a single point (<a href="...">3:5</a>) while others refer to a range of content (<a href="...">7:6-7:9</a>). Locator ranges
should be identified by using the epub:type locator-range. Examples 21-23 show different ways of encoding locator ranges.
- Structural Semantics Vocabulary
-
index-locator-range - Definition
-
Identifies an extent of content, rather than a single point
- Required Parent Context
-
index-entryorindex-locator-list - HTML Usage Context
-
Use on any [HTML5] flow content element
Must contain one or two elements carrying the child semantic
index-locators
Example 21, range tagged as a single a element designating only the beginning of the range; note that this provides no indication of where the range ends:
<ul epub:type="index-locator-list"> <li epub:type="index-locator-range"> <a href="chap2.xhtml#p076">76-79</a> </li> </ul>
Example 22, range tagged as a single a element designating the entire range, using Canonical Fragment Identifiers
[EPUBCFI]:
<ul epub:type="index-locator-list"> <li epub:type="index-locator-range"> <a href="epubcfi(/6/4[chap01ref]!/4[body01], /156[para76]/1:0, /170[para79]/1:0)">76-79</a> </li> </ul>
Ranges may also be encoded using two a elements, the first designating the beginning of the range and the second designating the end of the range, wrapped in an element with an epub:type attribute value of index-locator-range.
Example 23, range tagged as two a elements:
<ul epub:type="index-locator-list"> <li epub:type="index-locator-range"> <a href="chap2.xhtml#p07.6">7.6</a>-<a href="chap2.xhtml#p07.9">7.9</a> </li> </ul>
› 2.2.6 Locator Target Structural Semantics
A locator
may contain information about the object to which it points -- for example, whether the locator points to a figure, a table, a footnote, etc. The structural semantics of each locator target may be indicated by the value of the epub:type attribute.
Index locators extend the suggested XHTML context of terms from the EPUB Structural Semantics Vocabulary
[StructureVocab] to include the a element; terms from other associated vocabularies may also be used, in accordance with
Vocabulary Association
[ContentDocs301]
guidelines.
Example 24, locator with structural semantic information:
<!-- note use of "figure" "table" and "footnote" --> <a href="..." epub:type="index-locator figure">18</a> <a href="..." epub:type="index-locator table">345-349</a> <a href="..." epub:type="index-locator footnote">28</a>
› 2.2.7 Cross-references
A cross-reference conveys two types of information: (1) the cross-reference type (preferred or related), and (2) the destination term(s) or term category(ies). Therefore, two separate epub:type values are required.
note
This distinction between preferred and related cross-references parallels the use of see and seealso elements in [DocBook], the use of index-see and index-see-also elements in [DITA], and the use of the type attribute to further inflect the ref element in [TEI].
A cross-reference usually begins with different lead-in text to indicate to the user which type it is, such as "see" (for preferred cross-references) or "see also" (for related cross-references).
To indicate whether a cross-reference is related or preferred, use one of the following epub:type values:
index-xref-preferred directs user to preferred term(s) or term category(ies) |
index-xref-related directs user to related term(s) or term category(ies) |
In addition, to indicate whether the referenced item is a term or term category, use one of the following epub:type values:
index-term refers to a term
|
index-term-category refers to a term category
|
- Structural Semantics Vocabulary
-
index-xref-preferred
index-xref-related - Definition
-
Reference from one term to one or more other terms or term categories
- Required Parent Context
-
index-entry - HTML Usage Context
-
Use on any [HTML5] flow content element
Must contain one or more elements carrying the child semantic
index-terms orindex-term-categorys OR be carried on the same element asindex-termorindex-term-category
- Structural Semantics Vocabulary
-
index-term-category - Definition
-
Word, phrase, string, glyph or image representing a category of terms (e.g. "names of specific battles")
- Required Parent Context
-
index-xref-preferredorindex-xref-relatedAlternatively, may be carried on the same element as
index-xref-preferredorindex-xref-related - HTML Usage Context
-
Use on [HTML5]
aelement
Note that examples 25-32 in this section all have lead-in text (e.g., "see", "see also") hard-coded into the document. These could be omitted and generated by a [CSS2.1] style sheet instead, if preferred. Refer to 2.2.9 Punctuation and Lead-In Words for more on this.
A single element may carry both necessary epub:type values when there is a single cross-reference target, as shown in Example 25.
Example 25, cross-reference encoded on a single element:
<a href="..." epub:type="index-xref-preferred index-term">Beijing</a>
Alternatively, if there are multiple cross-reference targets, the two epub:type values may be carried on different elements to avoid having to repeat the "preferred" or "related" information for each one, as shown in Example 26.
Example 26, cross-reference encoded on separate elements:
<span epub:type="index-xref-related>See also <a href="..." epub:type="index-term">glucose</a>, <a href="..." epub:type="index-term">sucrose</a>. </span>
A cross-reference
may include an IRI [RFC3987] in the href attribute, such that the reading system may make it actionable.
The following three examples illustrate cross-reference options that direct the user to a specific term. Note that in each case the value of the href attribute in the cross-reference matches the id attribute of the corresponding index-entry, so the link will be actionable.
Example 27, cross-reference to a preferred term:
<!-- note id attribute beij --> <li epub:type="index-entry" id="beij"> <span epub:type="index-term">Beijing</span> <a epub:type="index-locator">113-120</a> </li> ... <li epub:type="index-entry"> <span epub:type="index-term">Peking</span> <span epub:type="index-xref-preferred">See <!-- note href attribute #beij --> <a epub:type="index-term" href="#beij">Beijing</a> </span> </li>
Example 28, cross-reference to a related term:
<li epub:type="index-entry"> <span epub:type="index-term">sweet potatoes</span> <span epub:type="index-xref-related">See also <!-- note href attribute #yams --> <a epub:type="index-term" href="#yams">yams</a> </span> </li> ... <!-- note id attribute yams --> <li epub:type="index-entry" id="yams"> <span epub:type="index-term">yams</span> <a epub:type="index-locator">93-97</a> </li>
Example 29, cross-reference to multiple terms:
<!-- note id attribute --> <li epub:type="index-entry" id="blig"> <span epub:type="index-term">blight (potato)</span> <a epub:type="index-locator">72-73</a> </li> ... <!-- note id attribute --> <li epub:type="index-entry" id="gray"> <span epub:type="index-term">gray mold</span> <a epub:type="index-locator">85</a> </li> ... <li epub:type="index-entry"> <span epub:type="index-term">potato diseases</span> <a epub:type="index-locator">21-25</a> <span epub:type="index-xref-related">See also <!-- href attributes matching id's --> <a epub:type="index-term" href="#blig">blight (potato)</a>, <a epub:type="index-term" href="#gray">gray mold</a>, <a epub:type="index-term" href="#powd">powdery mildew</a> </span> </li> ... <!-- note id attribute --> <li epub:type="index-entry" id="powd"> <span epub:type="index-term">powdery mildew</span> <a epub:type="index-locator">93-97</a> </li>
Examples 30-31 show generic cross-reference targets.
note
Unlike the above examples, which require only a valid href to make them actionable, actionable generic cross-reference targets require certain content in the
Navigation Document
[ContentDocs301]
as well. See 2.2.8 Term Categories and Generic Cross-Reference Targets for details.
Example 30, cross-reference to category of preferred terms:
<li epub:type="index-entry"> <span epub:type="index-term">battles</span> <span epub:type="index-xref-preferred">See <a epub:type="index-term-category" href="nav.xhtml#battles">names of specific battles</a> </span> </li>
Example 31, cross-reference to category of related terms:
<li epub:type="index-entry"> <span epub:type="index-term">battles</span> <a epub:type="index-locator" href="...">18-25</a> <a epub:type="index-locator" href="...">28-32</a> <span epub:type="index-xref-related">See also <a epub:type="index-term-category" href="nav.xhtml#battles">names of specific battles</a> </span> </li>
Finally, a cross-reference may direct the user to both term(s) and categorie(s).
Example 32, cross-reference to three terms and one term category:
<li epub:type="index-entry"> <span epub:type="index-term">yams</span> <a href="..." epub:type="index-locator">82</a> <span epub:type="index-xref-related">See also <!-- references to specific index terms --> <a epub:type="index-term" href="#yfes">Yam Festival (Ghana)</a> <a epub:type="index-term" href="#ypow">yam powder</a> <a epub:type="index-term" href="#yrec">yam recipes</a> <!-- reference to category of terms --> <a epub:type="index-term-category" href="nav.xhtml#yamcult">names of yam cultivars</a> </span> </li>
› 2.2.8 Term Categories and Generic Cross-Reference Targets
› 2.2.8.1 Overview
This section is informative
In the case of a generic cross-reference -- that is, one whose target is a term category rather than a term -- that reference can be actionable or non-actionable. Consider Example 31 above, which might appear in a book on the American Civil War. It is a non-actionable cross-reference as shown by the absence of an href attribute:
<li epub:type="index-entry"> <span epub:type="index-term>battles</span> <span epub:type="index-xref-preferred">See <a epub:type="index-term-category">names of specific battles</a></span> </li>
If this is left non-actionable, the user would have to know (or try to guess) all the names of battles, and then browse or search the index to see if those names are present. If the user does not guess correctly he may miss some pertinent entries or waste time looking for entries that don't appear in the index. In print books there is no remedy for this, but ebook technology offers a better option: provide the end user with a complete list of all the battles in the index, which they can easily access from this cross-reference.
Fully implemented, this provides extremely useful functionality that is not available in a traditional paper index. When the user encounters this type of cross-reference, she clicks on the phrase "names of specific battles" and the reading system takes her to the list of terms in the matching category. The user then selects the desired term and the reading system takes her to that term in the index. The user can then select the desired locator(s) to go to the discussion in the text. (See C.8 Enhancements to Term Categories and Generic Cross-Reference Targets for more on this.)
› 2.2.8.2 Navigating to Term Categories
To accomplish this, (1) the
Navigation Document
[ContentDocs301]
must include a nav element which has the epub:type attribute value of index-term-categories, and which contains a complete list of relevant index terms; and (2) the cross-reference in the index must have an epub:type attribute value index-term-category and an href attribute value pointing to that list. The requirements for the Navigation Document are outlined in section 2.4.2. Term Categories Support. The requirements for the index document are shown below.
Example 33, index document coding for a term category:
<li epub:type="index-entry"> <span epub:type="index-term">battles</span> <span epub:type="index-xref-preferred">See <!-- note href attribute, pointing to nav document --> <a epub:type="index-term-category" href="nav.xhtml#battles">names of specific battles</a> </span> </li> ... <!-- note id attribute --> <li epub:type="index-entry" id="chan"> <span epub:type="index-term">Chancellorsville</span> <a epub:type="index-locator" href="...">65</a> </li> ... <!-- note id attribute --> <li epub:type="index-entry" id="man1"> <span epub:type="index-term">First Manassas</span> <a epub:type="index-locator" href="...">58</a> </li> ... <!-- note id attribute --> <li epub:type="index-entry" id="gett"> <span epub:type="index-term">Gettysburg</span> <a epub:type="index-locator" href="...">72-73</a> </li> ...
For other enhanced reading system functionality related to generic cross-reference targets that would improve the user experience, and which is made possible by this specification, see C.8 Enhancements to Term Categories and Generic Cross-Reference Targets.
› 2.2.9 Punctuation and Lead-In Words
This section is informative
As can be seen in the examples in 2.2.7 Cross-references and 2.2.8 Term Categories and Generic Cross-Reference Targets, indexes often employ punctuation or special formatting to separate information in an entry (e.g., a comma between locators, a colon following a term, a period at the end of an entry) or to visually distinguish components (e.g., italicizing cross-references). Indexes also often employ consistent lead-in text (e.g., "see" for preferred cross-references and "see also" for related cross-references). This punctuation, formatting and lead-in text could be explicitly hard-coded into the index or, if they are consistent, they could be omitted and dynamically inserted via a [CSS2.1] style sheet.
For example, suppose that this is the desired display to the end user. Note the use of colons, commas, periods and italics:
Paris: 53, 76-79, 92-98.
Peking: see Beijing.
Example 34, punctuation, lead-in words and formatting hard-coded in:
<li epub:type="index-entry"> <!-- colon following term --> <span epub:type="index-term">Paris</span>: <!-- hard-coded commas separating locators --> <a epub:type="locator" href="...">53</a>, <a epub:type="locator" href="...">76-79</a>, <a epub:type="locator" href="...">92-98</a>. </li> ... <li epub:type="index-entry"> <!-- colon following term --> <span epub:type="index-term">Peking</span>: <!-- hard-coded italics, lead-in word "see" --> <span epub:type="index-xref-preferred"><i>see </i> <!-- period following term --> <a epub:type="index-term" href="...">Beijing</a>. </span> </li>
Example 35, punctuation omitted:
<li epub:type="index-entry"> <!-- no colon following term --> <span epub:type="index-term">Paris</span> <!-- no commas between locators or period at the end --> <a epub:type="locator" href="...">53</a> <a epub:type="locator" href="...">76-79</a> <a epub:type="locator" href="...">92-98</a> </li> ... <li epub:type="index-entry"> <!-- no colon following term --> <span epub:type="index-term">Peking</span> <span epub:type="index-xref-preferred"><i>see </i> <!-- no period following term --> <a epub:type="index-term" href="...">Beijing</a> </span> </li>
Example 36, punctuation, formatting and lead-in words omitted:
<li epub:type="index-entry"> <span epub:type="index-term">Paris</span> <a epub:type="locator" href="...">53</a> <a epub:type="locator" href="...">76-79</a> <a epub:type="locator" href="...">92-98</a> </li> <li epub:type="index-entry"> <span epub:type="index-term">Peking</span> <span epub:type="index-xref-preferred"> <a epub:type="index-term" href="...">Beijing</a> </span> </li>
› 2.3 Identification of an Index
Indexes must be identified in the package document, regardless of whether they are a component of a larger publication or represent the publication itself. Depending on the type of publication, either the package document metadata [Publications301] or manifest [Publications301] identifies this nature.
note
This information may be used by the reading system to do any necessary preprocessing of indexes when opening an EPUB Publication.
› 2.3.1 Identification of a Publication Containing Only Index(es)
If the publisher wishes to identify the primary purpose of the publication as an index, the publication should be identified as a specialized type by including a dc:type [DCMIType] element in the package metadata with the specific nature.
Example 37, entire publication is index:
<metadata> ... <dc:type>index</dc:type> ... </metadata>
› 2.3.2 Identification of Index Content Document(s)
› 2.3.2.1 Single-File Index(es)
If an index is wholly contained in a single content document, as described in section 2.2.1, each content document containing an index must have the property of index on the content document's manifest item.
Example 38, index consists of one content document:
<manifest> <item href="index01.xhtml" properties="index" ... /> </manifest>
The index property is implied on the manifest item when the entire publication is defined as an index, as described in 2.3.1 above.
› 2.3.2.2 Multi-File Index(es) and the collection Element
If a single index is distributed across multiple content documents, the index content must be identified using the collection element of the package document with the role attribute set to index [DCMIType]. This must be done even when the primary purpose of the publication is identified as an index, as described in section 2.3.1.
The index role defined in this specification restricts the collection element as follows:
-
May include child
collectionelements -
Child
collectionelements must have theroledefined asindex-group -
Links must resolve to content documents or fragments
note
The sequence of link elements in the collection does not affect rendering of elements in the spine
[Publications301].
note
An index should be processed by a Reading System in the same manner, whether it is a single content document or multiple content documents grouped by a collection. This enables the functionality discussed in Appendix C. Reading System Implementation Suggestions.
Example 39, publication contains two separate indexes, each identified by a collection element:
<package> ... <collection role="index"> <link href="subjectIndex01.xhtml" /> <link href="subjectIndex02.xhtml" /> <link href="subjectIndex03.xhtml" /> </collection> <collection role="index"> <link href="chap1.xhtml#nameIndex1" /> <link href="chap2.xhtml#nameIndex2" /> </collection> ... </package>
The index-group role defined in this specification restricts the collection element as follows:
-
index-groupmust be a sub-collection of a collection with a role ofindex -
It must not contain further sub-collections
-
Links must resolve to content documents or fragments
note
The sequence of link elements in the sub-collection does not affect rendering of elements in the spine [Publications301].
note
An index group should be processed by a Reading System in the same manner, whether it is a single content document or multiple content documents grouped by a sub-collection. This enables the functionality discussed in Appendix C. Reading System Implementation Suggestions.
Example 40, publication contains an index with index-groups, some of which “span” multiple content documents. These are identified by using a child collection element with role="index-group":
<package>
...
<collection role="index">
<collection role="index-group">
<link href="subjectIndex-a01.xhtml" />
<link href="subjectIndex-a02.xhtml" />
<link href="subjectIndex-a03.xhtml" />
</collection>
<link href="subjectIndex-b.xhtml" />
<collection role="index-group">
<link href="subjectIndex-c01.xhtml" />
<link href="subjectIndex-c02.xhtml" />
<link href="subjectIndex-c03.xhtml" />
</collection>
<link href="subjectIndex-d.xhtml" />
<link href="subjectIndex-e.xhtml" />
...
</collection>
...
</package>
› 2.4 The Navigation Document
› 2.4.1 General Recommendations
The Navigation Document [ContentDocs301] should point to all indexes. The landmarks nav element [ContentDocs301] should include links to indexes as well as to any index groups present.
Example 41, landmarks element with links to index and index group data:
<nav epub:type="landmarks">
<h2>Guide</h2>
<ol>
<li><a epub:type="toc" href="#toc">Table of Contents</a></li>
<li><a epub:type="loi" href="content.xhtml#loi">List of Illustrations</a></li>
<li><a epub:type="bodymatter" href="content.xhtml#bodymatter">Start of Content</a></li>
<li><a epub:type="index" href="index.xhtml#idx1">Subject Index</a>
<ol hidden="">
<li><a epub:type="index-group" href="index.xhtml#A">A</a></li>
<li><a epub:type="index-group" href="index.xhtml#B">B</a></li>
...
</ol>
</li>
<li><a epub:type="index" href="index.xhtml#idx2">Author Index</a></li>
</ol>
</nav>
› 2.4.2 Term Categories Support
An actionable generic cross-reference requires a generic cross-reference target in the index and an associated term category in the Navigation Document [ContentDocs301] . Section 2.2.8 describes how to create a generic cross-reference target in the index. This section explains how to create the term category structure in the Navigation Document.
The nav element containing the term categories must have its epub:type attribute set to index-term-categories.
- Structural Semantics Vocabulary
-
index-term-categories - Definition
-
Wrapper for list of terms belonging to an index term category.
- HTML Usage Context
-
Use on
navMay be repeated
In the EPUB
Navigation Document
[ContentDocs301]
, the index-term-categories
nav element contains a list of all the term categories, and each term category contains all the terms that are part of that category. Each a has an href attribute value pointing to that term's entry in the index document. The
Navigation Document
[ContentDocs301]
may contain more than one nav element with the epub:type attribute value index-term-categories (for example, in a publication with multiple indexes, the publisher may wish to have a separate index-term-categories for each index).
Example 42, term category support in the navigation document:
<nav epub:type="index-term-categories" hidden=""> <!-- hidden attribute prevents term categories from being rendered in the content flow --> <ul> <li id="battles">battles <ol> <!-- a's pointing to all terms in this term category --> <li><a href="index.xhtml#chan">Chancellorsville</a></li> <li><a href="index.xhtml#man1">First Manassas</a></li> <li><a href="index.xhtml#gett">Gettysburg</a></li> </ol> </li> ... <!-- more than one term category may be included --> <li id="generals">Confederate generals <ol> <li><a href="index.xhtml#grant">Grant, Ulysses S.</a></li> <li><a href="index.xhtml#lee">Lee, Robert E.</a></li> <li><a href="index.xhtml#pick">Pickett, George</a></li> </ol> </li> </ul>
note
As the index-term-categories
nav element is typically not intended to be rendered to the user as part of the content flow, it should typically carry the
hidden
[ContentDocs301]
attribute.
› 3 Conformance Criteria
› 3.1 Content Conformance
An EPUB Publication [Publications301] that complies with this specification must meet all of the following criteria:
| It must be a valid EPUB Publication as defined in [Publications301] |
| Its Package Document [Publications301] [MediaOverlays30] must contain metadata that complies with section 2.3 of this specification. |
| Its Navigation Document [ContentDocs301] [ContentDocs30] should conform to the additional requirements detailed in section 2.4 of this specification. |
It must contain at least one content document with at least one element whose epub:type attribute has the value index, whose content model complies with section 2.2.1 of this specification. |
› 3.2 Reading System Conformance
This specification has no additional Reading System Conformance criteria beyond what is required by EPUB 3.0.1.
› Appendix A. Schema for Indexes in EPUB Content Documents
The additional schema for XHTML Content Documents conforming to the EPUB Indexes specification is available at http://www.idpf.org/epub/idx/schema/epub-idx-10.sch.
› Appendix B. Examples
This appendix is informative
› B.1 Simplest possible index
An example of the simplest possible index conforming to this specification is shown below.
<html xmlns="http://www.w3.org/1999/xhtml" xmlns:epub="http://www.idpf.org/2007/ops" xml:lang="en-US" lang="en-US"> <head> <meta charset="UTF-8"/> <title>Simplest Index</title> </head> <body epub:type="index"> <h2>Simplest index</h2> <ul epub:type="index-entry-list"> <!-- epub:type index-entry is implied for all li's, due to ancestor with epub:type of index-entry-list --> <li><span epub:type="index-term">abbreviations</span>, <a epub:type="index-locator" href="...">52</a></li> <li><span epub:type="index-term">accents</span>, <a epub:type="index-locator" href="...">20</a></li> <li><span epub:type="index-term">blogs</span>, <a epub:type="index-locator" href="...">98</a></li> <li><span epub:type="index-term">cold calling</span>, <a epub:type="index-locator" href="...">68</a></li> <li><span epub:type="index-term">Facebook</span>, <a epub:type="index-locator" href="...">viii</a>, <a epub:type="index-locator" href="...">96</a></li> <li><span epub:type="index-term">inversion</span>, <a epub:type="index-locator" href="...">53</a></li> <li><span epub:type="index-term">Twitter</span>, <a epub:type="index-locator" href="...">37-42</a></li> </ul> </body> </html>
› B.2 Full example
An example of a more complicated index, including subentries, cross-references, term categories, and so on, is available here.
An associated sample Navigation Document is available here. As noted in 2.4.2. Term Categories Support, the item-categories
nav element is un-hidden in order to demonstrate actionable generic cross-reference targets.
See also the index to this specification in Appendix E for additional examples.
› B.3 Sample style sheet
As mentioned in 2.2.9 Punctuation and Lead-In Words, punctuation and lead-in words could be omitted from the index code and inserted via a [CSS2.1] style sheet using the :before pseudo-element. This would ensure consistency and reduce the size of the index document.
› Appendix C. Reading System Implementation Suggestions
This appendix is informative
Basic index functionality, where the index is positioned as the last chapter with or without actionable links, is already provided in some EPUB Publications. This specification makes possible a host of new features and functionality, some of which are described in the following paragraphs. It is hoped that RS manufacturers and developers will exploit these and other new possibilities.
› C.1 General Reading System Features Relative to Indexes
As stated in 3.2 Reading System Conformance, an index encoded according to this specification has the same Reading System Conformance criteria as that defined in EPUB 3.0.1 in order to be minimally functional -- that is, it can be accessed from the Table of Contents and paged through in a linear fashion.
However, due to the unique nature of indexes and the way in which users interact with them, we present below a minimum set of functionality that this specification makes possible.
A Reading System would ideally allow the user to:
-
display any legend(s), if present, from anywhere in the index without having to navigate to the top.
-
display the head notes, if present, from anywhere in the index without having to navigate to the top.
-
easily navigate to a specific index group without having to return to the Navigation Document / Table of Contents (e.g., by displaying a persistent floating alphabet bar so that the user can click on a letter to go to that group).
-
navigate to the index(es) without having to return to the Navigation Document / Table of Contents (e.g., by enabling one-click access to the index from within the text, or presenting the index in a separate window from the text so that both are accessible concurrently).
-
include or exclude the index from searches -- that is, to search only the body of the publication, only the index(es), or both.
-
view or access currently applicable ancestor terms up to the main entry term without scrolling up ("breadcrumb trail") (see C.9 Improved Index Navigation).
› C.2 Search Parameters
The Package Document identifies when one or more indexes are present in an EPUB Publication and provides information about whether an index is a part of an XHTML file, is a single XHTML file, or is comprised of more than one XHTML files. (See 2.3 Identification of the Index in the Package Document). This information could allow the reading system to offer the user choices about which index(es) to include as the user interacts with the EPUB. For example, the reading system could allow the user to browse the index directly as a content document, but also to include/exclude index(es) from the basic search (that is, search only the text, search text plus indexes, search one index only, or search all indexes.
› C.3 Index Term Search
Unlike tables of contents, indexes are often used in a "back and forth" manner in conjunction with the text. That is, users often go from the text to the index and back again to locate all pertinent information. The reading system could support users in this by enabling the user to go straight to a location in the index, either by highlighting words in the text or by invoking search and inputting a search term, without losing their place in the text.
For example, the user could select a word or phrase in the text and then trigger a display of all matching index entries; the user could then choose to click one of the terms to switch to the index, click a locator to be taken to another place in the text, or close the display and return to her original location in the text. (Reading systems that have a "back" button somewhat provide this functionality already.)
The reading system could also allow the user to open a search box, type in a search phrase, and trigger a display of any matching index entries. Hits from the index could be presented alone or alongside search results from the text and other parts of the book such as the glossary. This would provide a one-stop-shop that allows the user to select the content most appropriate to them at the time.
› C.4 Index Locator Search
Reading systems could traverse the links between locators in the index and their targets in the text in a reverse direction, to retrieve all index entries associated with a selected range of text. So, for example, a user could select a range of text containing topics of interest to him and trigger a display of all the index entries that contain locators pointing to somewhere in the selected segment.
Reading systems could exploit and implement this in a variety of useful ways:
-
The reading system takes the user to the index and filters it to display only the relevant terms
-
The reading system displays the relevant index terms in a pop-up window; the user selects the desired term; the reading system takes the user to that term in the index
-
The reading system displays the relevant index terms and all their associated locators in a pop-up window; the user selects the desired locator; the reading system takes the user to that target in the text
Reading system developers no doubt will think of other possibilities.
› C.5 Highlighting of Locator Ranges
Reading systems could exploit locator ranges, if the start and end points are identified as discussed in 2.2.5 Locator Ranges, as follows: When the user clicks on a locator range, the reading system could take the user to the target in the text and highlight the specified range. This clear indication would help the user quickly identify the relevant passages and thus know where to start and stop reading.
› C.6 Filtering of Indexes
As mentioned briefly in 2.2.6 Locator Target Structural Semantics, information about the nature of a locator's target could be exploited by the reading system to allow users to filter an index according to their specific requirements. For example, users could filter the index to show only terms and associated locators that point to tables, or to figures, or to some other structural component. Users who only wanted to see images would therefore not have to browse past dozens of locators pointing to text.
Multiple indexes are frequently used in highly complex or lengthy books -- for example, a history of World War II might include a subject index, an index of battles, and a name index. This requires the user to choose between multiple indexes to find a desired term, possibly wasting time and energy. Presenting all of these in a single index filterable by term category would simplify the user experience.
This ability to display/render only subsets of a content document is of general interest in ebooks, not only to indexes. The minimal solution at this time is to employ alternate [CSS2.1] style sheets in conjunction with structural semantic information (2.2.6):
<!-- a persistent style sheet --> <link rel="stylesheet" href="default.css"> <!-- some alternate style sheets --> <link rel="alternate stylesheet" href="figures.css" title="Show only figure entries/locators" class="figures"/> <link rel="alternate stylesheet" href="tables.css" title="Show only table entries/locators" class="tables"/>
It is to be hoped that more sophisticated reading systems and enhanced encoding options will eventually remove the need for alternate style sheets and allow "on the fly" filtering based on metadata within the index entries themselves. For example, many technical books include a List of Figures at the beginning of the book, which lists all figures in the order they appear in the text. If a reading system had the built-in ability to filter by epub:type value, an index could be filtered to show only terms with locators that point to figures, in effect generating a List of Figures sorted by topic. The ability to view only a desired subset of a large index is a functionality impossible in the paper book/index environment and could potentially be useful to users.
› C.7 Provision of Additional Information about Locator Targets
As mentioned briefly in 2.2.6 Locator Target Structural Semantics, reading systems could exploit the presence of information about the nature of a locator's target to give the end user information about what type of "thing" they will find if they traverse a locator link. For example, if a user hovers over or otherwise places focus on a properly-encoded locator that points to a figure ( <a epub:type="index-locator figure">), a "tool-tip"-style pop-up could display a cue (e.g., the word "fig" or "table", or the letter "f" or "t") to let the user know this.
Reading systems could exploit the link between a locator and its target in the text to display a tool-tip-style pop-up containing a portion of the content on either side of the target (or, if the target is a range, a portion of the range), as a sort of preview, when the user hovers over or otherwise places focus on a locator. This would enable the user to get a sense of the context in which the target appears at that location, and choose whether or not to traverse the link. (Obviously, the greater the precision in placement of anchors within the text, the greater the usefulness of this functionality.) Many search engines already offer this feature in their display of search results, so users are accustomed to it.
› C.8 Enhancements to Term Categories and Generic Cross-Reference Targets
Section 2.2.8 Term Categories and Generic Cross-Reference Targets discusses the use of predefined lists to enable the use of term categories as targets. This solution, while immediately workable, requires several clicks for the user to get to his end goal.
Reading systems might mitigate this problem by displaying term categories in a pop-up window or separate frame, so that the user can view both the original cross-reference in the index and the list of terms in that category and select the term he wishes.
As with C.6 Filtering of Indexes, it is to be hoped that more sophisticated reading systems and enhanced encoding options will eventually do away with the need for static pre-defined term category lists. For example, a future version of EPUB might allow for embedding category information in the actual index term (something like <span epub:type="index-term" category="battle">Gettysburg</span>) and future reading systems could use that to dynamically locate and display to the user a list of all terms in a given category.
› C.9 Improved Index Navigation
Reading systems could exploit the nested wrapping of main entries and child entries in appropriate elements with the appropriate epub:type values to allow users to expand or collapse main entries or entire groups of entries; for example, the default index presentation could display only main entries, and then, when the user finds a main entry they want to explore, they could expand it to show locators and/or subentries. The reading system could also offer an "Expand" or "Collapse" to quickly show or hide all subentries in an index or index group; this ability to reduce the index down would allow the user to browse through the main entry terms more quickly.
Nested wrapping could also be exploited to display a persistent "breadcrumb" trail at the top of the screen as the user scrolls down through the index, showing the currently applicable parent entries all the way up to the main entry. This would ensure that the user always has access to the full hierarchical structure of an entry.
Reading systems could exploit the presence of epub:type values for head notes and legend to allow the user to access this information from any location in the index, without forcing him to scroll back to the top of the document.
Reading systems could exploit the presence of the epub:type value index-group to enable group navigation of the index, rather than forcing the user to scroll through the entire index manually. For example, the reading system could display a horizontal alphabet bar so the user could click on a particular letter and go straight to that group.
› Appendix D. Alphabetical list of epub:types defined in this specification
The following epub:type values are defined in this specification.
› Appendix E. Index to this specification
An index to this specification document has been created, including web-simulated term-categories.
The same index content is also available tagged for an EPUB3 Publication, according to this specification, and may serve as another example. The associated structures from the nav document and package document that relate to the index are also available.
› Appendix F. Acknowledgements and Contributors
This appendix is informative
EPUB has been developed by the International Digital Publishing Forum in a cooperative effort, bringing together publishers, vendors, software developers, and experts in the relevant standards.
The EPUB 3 Indexes Specification 1.0 was prepared by the International Digital Publishing Forum's Indexes Working Group, operating under a charter approved by the membership in December, 2011 under the leadership of:
- Browne, Glenda (Australia and New Zealand Society of Indexers (ANZSI)) Co-secretary
- Combs, Michele (American Society for Indexing (ASI)) Co-chair
- Gylling, Markus (DAISY Consortium) Advisor
- Ream, David (Leverage Technologies; American Society for Indexing (ASI)) Co-chair
- Siegman, Tzviya (John Wiley & Sons) Co-secretary
Active members of the working group at the time of publication were:
› IDPF Members
- Audrain, Luc (Hachette Livre)
- Broome, Karen (Sony)
- Chow, King-Wai (Hong Kong Applied Science & Technology Research Institute Company Limited (ASTRI))
- Deltour, Romain (DAISY Consortium)
- Echallier, Nicholas (Nordcompo Multimedia)
- Haas, Matt (Pearson)
- Kaplansky, Jean (Aptara)
- Kasdorf, Bill (Apex CoVantage)
- Kida, Yasuo (Apple Inc.)
- MURATA, Makoto (Japan Electronic Publishing Association (JEPA))
- Russell, Mary (Australia and New Zealand Society of Indexers (ANZSI))
- Sorotokin, Peter (Google)
- Wright, Jan (American Society for Indexing (ASI))
› Invited Experts/Observers
- Bolick, Bob
- Garrish, Matt
- Prentice, Scott
› References
Normative References
[CSS2.1] Cascading Style Sheets Level 2 Revision 1 (CSS 2.1) Specification . 7 June 2011.
[ContentDocs30] EPUB Content Documents 3.0 .
[ContentDocs301] EPUB Content Documents 3.0.1 .
[DCMIType] DCMI Type Vocabulary. DCMI Usage Board, 11 October 2010.
[MediaOverlays30] EPUB Media Overlays 3.0 .
[Publications301] EPUB Publications 3.0.1 .
[RFC2119] Key words for use in RFCs to Indicate Requirement Levels (RFC 2119) . March 1997.
[RFC3987] Internationalized Resource Identifiers (IRIs) (RFC 3987) . January 2005.
[StructureVocab] EPUB 3 Structural Semantics Vocabulary .
Informative References
[DocBook] DocBook Specifications .
[NISOTR02] NISO Technical Report 2: Guidelines for Indexes and Related Information Retrieval Devices .
[TEI] TEI: P5 Guidelines .